Dans l'univers en constante évolution de l'intelligence artificielle et du traitement du langage naturel, txtai émerge comme un outil révolutionnaire, surtout pour ceux qui plongent dans le monde des modèles de langage à grande échelle (LLMs). Imaginez un pont entre vous et un éventail de LLMs puissants, où txtai joue le rôle d'intermédiaire facilitant, simplifiant et amplifiant vos interactions avec ces technologies complexes.
Connectivité Étendue avec les LLMs
Txtai se distingue par sa capacité à se connecter à divers LLMs. Que ce soit GPT-3, BERT, ou d'autres modèles de pointe, txtai agit comme un canal unifié, vous permettant d'accéder à ces puissances de calcul sans les tracas de configurations complexes. Pour le développeur, cela signifie une réduction significative du temps et des efforts nécessaires pour intégrer ces modèles dans leurs applications.
Fonctionnalités Préconfigurées pour une Facilité d'Utilisation
L'un des atouts majeurs de txtai est la pré-configuration de ses diverses fonctions de traitement de texte. Classification, résumé, traduction, et bien d'autres tâches de NLP sont prêtes à l'emploi, ne nécessitant qu'une intervention minimale du développeur. Cette facilité d'utilisation rend txtai particulièrement attrayant pour ceux qui souhaitent exploiter la puissance des LLMs sans se plonger dans les détails techniques.
Workflow Personnalisable pour des Tâches Groupées
La véritable magie de txtai réside dans sa capacité à grouper des tâches dans des workflows personnalisables. Cela ouvre un potentiel immense pour les entreprises en leur permettant de chaîner des opérations de NLP en séquences logiques, automatisant ainsi des processus complexes. Que ce soit pour analyser des sentiments, générer des résumés de documents, ou effectuer des recherches approfondies, txtai rend ces tâches non seulement possibles, mais aussi étonnamment simples.
Recherches Intelligentes et Plus Encore
Au-delà des recherches textuelles basiques, txtai excelle dans la réalisation de recherches intelligentes, comprenant le contexte et la nuance des requêtes. Cette capacité à interpréter et à répondre de manière intelligente aux demandes de recherche rend txtai non seulement un outil puissant pour les développeurs, mais aussi un atout stratégique pour les entreprises cherchant à exploiter au maximum les données textuelles.
En résumé, txtai n'est pas seulement un outil, c'est un facilitateur, un amplificateur de possibilités dans le domaine de l'intelligence artificielle et du traitement du langage naturel. Avec txtai, les développeurs ont un accès sans précédent à une gamme de fonctionnalités avancées en NLP, tout en bénéficiant d'une simplicité d'utilisation et d'une adaptabilité exceptionnelles.
Pour vous donner un exemple tres rapide de ce que peut faire txtAi en quelques lignes voici un premier exemple tiré de la documentation officielle : https://github.com/neuml/txtai/blob/master/examples/01_Introducing_txtai.ipynb
sequences:
path: google/flan-t5-small
workflow:
chain:
tasks:
- task: template
template: Translate '{statement}' to {language} if it's English
action: sequences
- task: template
template: What language is the following text? {text}
action: sequences
On lance un server:
CONFIG=workflow.yaml /usr/local/bin/uvicorn "txtai.api:app"
Et hop, cablé directement avec FastApi, vous avec directement une api prête à l'emploi
http://127.0.0.1:8000/docs vous donne directement accès à un espace swagger pour vous permettre de jouer avec votre configuration.
A présent lançons une requete sur notre API et analysons ce qu'il se passe. :
curl -X 'POST' \
'http://127.0.0.1:8000/workflow' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"name": "example1",
"elements":[
{"statement": "Hello, how are you", "language": "French"},
{"statement": "Hallo, wie geht'\''s dir", "language": "French"}
]
}'
La réponse sera :
[
"Czech",
"French"
]
Mais alors, qu'est-ce qu'il s'est passé ?
Rappelez-vous du workflow d'exemple :
sequences:
path: google/flan-t5-small
workflow:
chain:
tasks:
- task: template
template: Translate '{statement}' to {language} if it's English
action: sequences
- task: template
template: What language is the following text? {text}
action: sequences
Dans le tuyau, nous demandons au Modèle de "traduire en français si le message est Anglais", on passe directement la sortie de cette tache à la tâche suivante : "Donne-moi la langue de ce texte". Dans notre payload, la première phrase est Anglaise, alors le modèle va nous le traduire, dans la seconde, c'est en allemand, il ne nous la traduit pas. Mais alors pourquoi il ne nous reconnait pas la langue allemande ? En fait l'exemple officiel utilise google/flan-t5-large alors que moi j'ai mis le flan-t5-small. Moins précis. je recommence avec le t5-large et ça va me donner
[
"French",
"German"
]
Voilà qui est mieux, avec un modèle un peu plus gros, la précision est meilleure. Plus votre modèle est gros, plus vous allez avoir besoin d'un GPU avec de la RAM. Il y a un bon ratio à trouver entre le matériel nécessaire et la qualité de la réponse souhaité.
Vous aurez donc compris, avec très peu de lignes de codes, vous avez une API qui peut vous faire tout un tas de choses intéressantes. Vous pourrez indexer vos fichiers PDF, vos images, tous les documents de votre entreprise et faire des requêtes intelligentes dessus. Ou bien encore constituer une base de données pour des questions/réponses et interroger un moteur de recherche sémantique dans la langue de votre choix pour la langue de votre choix. Les possibilités n'ont de limites que votre imagination/besoin.
Alors tout ça, c'est super, mais si on a besoin d'un peu plus de flexibilité. On voit bien que dans la documentation la liste des Task est grande et la plupart des choses se font toutes seules. Sauf qu'on le sait bien. On est rarement dans un cas ou tout est déjà présent et c'est là qu'il faut commencer à faire les choses soit même à la main. Alors pour l'exemple, nous allons creer notre propre workflow, avec notre propre tache sur un endpoint qu'on nous aura même imaginé. Donc voici ce qu'on veut :
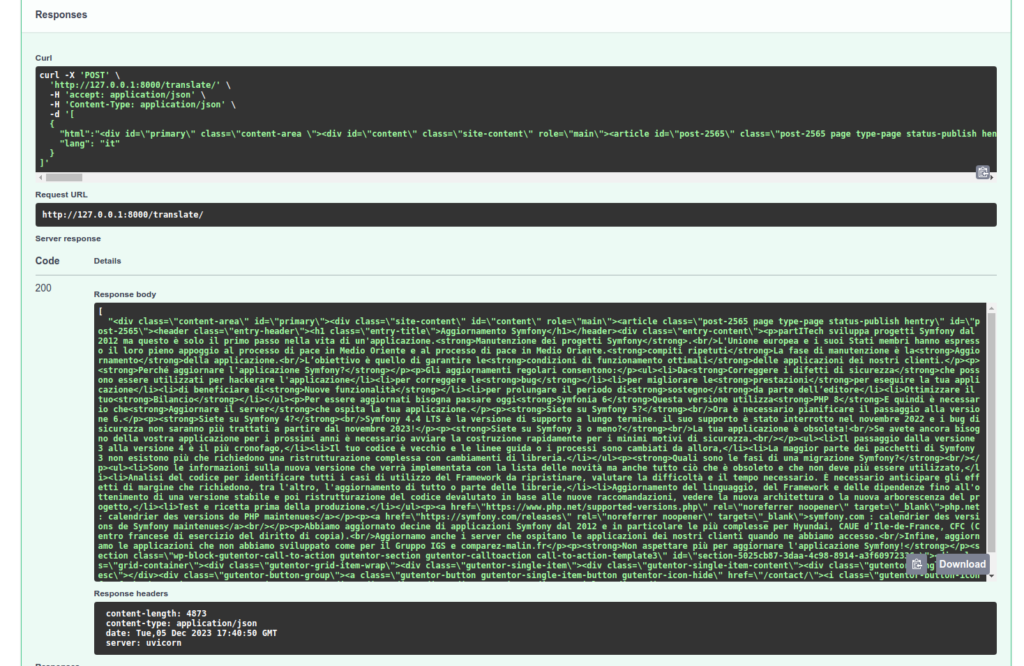
1- Un api du type : /translate en POST avec un payload de ce type :
[
{
"html": "Mon <div>text à</div> moi ",
"lang": "en"
}
]
JSON.stringify($('#test_json').html()) sur n'importe quel site vous donnera du contenu pour l'exemple.
- On veut donc récupérer du contenu HTML et le traduire. Et pour finir, bien entendu, retourner le résultat.
Vous allez me dire, c'est super simple. Et vous n'aurez pas tout à fait tort. Car ça l'est, en effet. Mais c'est comme tout, une fois qu'on a un exemple sous les yeux, c'est très simple. Les exemples simples n'étant pas légion, j'ai tout de même dû chercher et tâtonner un peu.
Je vous propose donc de lire le code, et les commentaires devraient vous aiguiller sur la marche à suivre.
Nous avons donc 2 fichiers : main.py et TranslateHtml.py. Main étant notre programme principal et TranslateHtml notre classe qui nous sert de tâche pour notre workflow.
from txtai.pipeline import Translation
from bs4 import BeautifulSoup
class TranslateHtml:
def __init__(self):
self.translate = Translation()
def __call__(self, datas):
results = []
for data in datas:
html = data['html']
lang = data['lang']
translated = self.translate_html(html, lang)
results.append(translated)
return results
def translate_html(self, html, lang):
html = html.replace("\/", "/")
soup = BeautifulSoup(html, 'html.parser')
for element in soup.find_all(string=True):
if element.parent.name in ['p', 'li', 'h1', 'h2', 'h3', 'span']:
original_text = element.string
translated_text = self.translate_to(original_text, lang)
if translated_text:
element.string.replace_with(translated_text)
return str(soup)
def translate_to(self, text, lang="fr"):
return self.translate(text, lang)
Nous avons donc une class, assez simple. Elle doit être callable et nous retourner un tableau de résultats. Je me suis, bien entendu, inspiré de la classe de la Task Translation pour voir comment devait s'organiser le code. Rappelons-le, l'idée est de faire une tâche personnalisée qui devrait pouvoir se chaîner avec les autres que l'on pourrait utiliser dans un workflow. À noter qu'il est même possible de créer des workflows de workflows. Ce qui peut être bien utile si on souhaite organiser ses tâches/workflows sous forme de briques bien élaborées.
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from fastapi.encoders import jsonable_encoder
from typing import List
from txtai.workflow import Workflow, Task
from TranslateHtml import TranslateHtml
# Définition du modèle Pydantic pour les données d'entrée
class TranslationRequest(BaseModel):
html: str
lang: str
# Initialisation de FastAPI
app = FastAPI()
# Déclaration de notre Tache perso
translate_html = TranslateHtml()
# Déclaration de notre workflow.
workflow = Workflow(
[
Task(lambda x: translate_html(x))
]
)
# Définition de l'endpoint POST
@app.post("/translate/")
async def translate(requests: List[TranslationRequest]):
try:
# Converti les requêtes Pydantic en dictionnaires
data = [jsonable_encoder(request) for request in requests]
# Exécution du workflow txtai
results = workflow(data)
return results
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
Remarquez notre workflow. Nous pourrions en enchaîner plusieurs à la suite afin de chaîner une liste de traitements complexes.
On lance notre serveur unicorn :
CONFIG=workflow.yaml /usr/local/bin/uvicorn "txtai.api:app"
export CUDA_VISIBLE_DEVICES="" && uvicorn main:app --reload
je mets CUDA_VISIBLE_DEVICES à vide pour dire "n'utlise pas mon GPU".
On va vérifier le traitement de notre API :
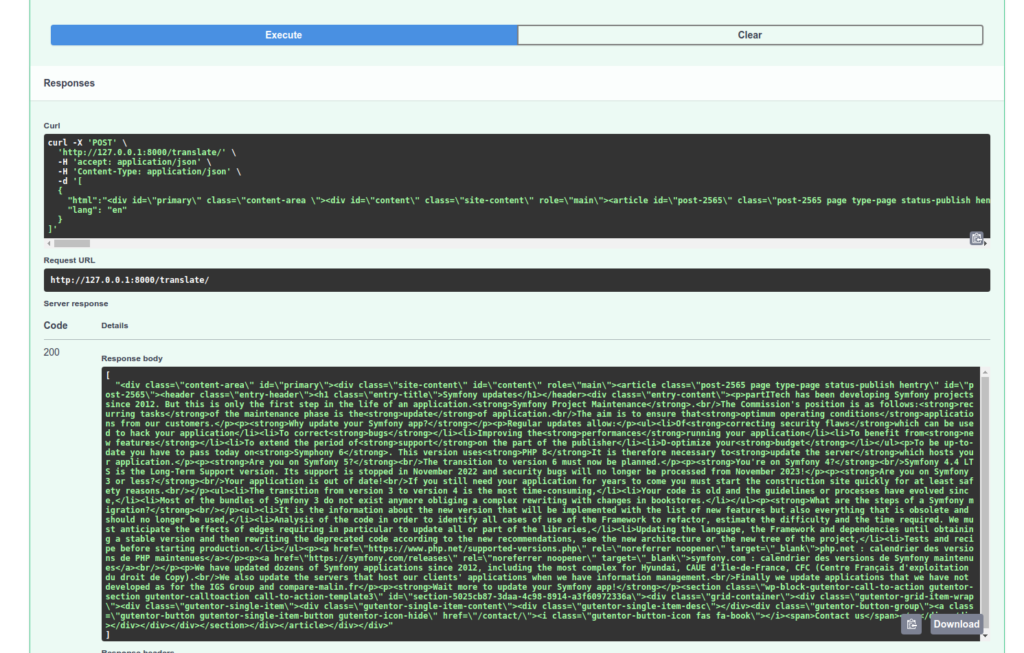
À noter que la tâche de référence translate utilisée dans notre Tâche de conversion TranslateHtml choisit automatiquement le modèle le plus approprié à votre traduction ! Aussi, si dans mon appel je change et je mets "it", ma première requête devra attendre le téléchargement du modèle adéquat.
Gardez en mémoire que d'autres modèles spécialisés feront un meilleur travail de traduction. GPT-4 notamment, mais d'autres services faits pour cette tâche seront plus adaptés. Et dans tous les cas, ça ne remplacera pas un vrai traducteur et une relecture. En revanche, ces traitements de textes seront suffisants pour classifier vos documents et requêter dessus.
Voici donc une première présentation de TxtAi, nous aurons l'occasion d'en reparler très prochainement car il constitue une superbe alternative à LlamaIndex.