En el universo en constante evolución de la inteligencia artificial y el procesamiento del lenguaje natural, txtai surge como una herramienta revolucionaria, especialmente para aquellos que se sumergen en el mundo de los modelos de lenguaje de gran escala (LLMs). Imagina un puente entre tú y una gama de potentes LLMs, donde txtai juega el papel de intermediario facilitando, simplificando y amplificando tus interacciones con estas tecnologías complejas.
Conectividad Ampliada con los LLMs
Txtai se distingue por su capacidad para conectarse con diversos LLMs. Ya sea GPT-3, BERT, u otros modelos punteros, txtai actúa como un canal unificado, permitiéndote acceder a estas potencias de cálculo sin los problemas de configuraciones complejas. Para el desarrollador, esto significa una reducción significativa del tiempo y el esfuerzo necesarios para integrar estos modelos en sus aplicaciones.
Funcionalidades Preconfiguradas para una Facilidad de Uso
Uno de los mayores activos de txtai es la preconfiguración de sus diversas funciones de procesamiento de texto. Clasificación, resumen, traducción y muchas otras tareas de NLP están listas para usar, requiriendo solo una intervención mínima del desarrollador. Esta facilidad de uso hace a txtai particularmente atractivo para quienes desean explotar la potencia de los LLMs sin ahondar en los detalles técnicos.
Flujo de Trabajo Personalizable para Tareas Agrupadas
La verdadera magia de txtai reside en su capacidad para agrupar tareas en flujos de trabajo personalizables. Esto abre un potencial inmenso para las empresas permitiéndoles encadenar operaciones de NLP en secuencias lógicas, automatizando así procesos complejos. Ya sea para analizar sentimientos, generar resúmenes de documentos o realizar búsquedas profundas, txtai hace estas tareas no solo posibles, sino también sorprendentemente simples.
Búsquedas Inteligentes y Más
Más allá de las búsquedas textuales básicas, txtai sobresale en la realización de búsquedas inteligentes, comprendiendo el contexto y la sutileza de las consultas. Esta capacidad para interpretar y responder de manera inteligente a las demandas de búsqueda convierte a txtai no solo en una herramienta poderosa para los desarrolladores, sino también en un activo estratégico para las empresas que buscan aprovechar al máximo los datos textuales.
En resumen, txtai no es solo una herramienta, es un facilitador, un amplificador de posibilidades en el ámbito de la inteligencia artificial y el procesamiento del lenguaje natural. Con txtai, los desarrolladores tienen acceso sin precedentes a una gama de funciones avanzadas en NLP, mientras disfrutan de una simplicidad de uso y una adaptabilidad excepcionales.
Para darte un ejemplo muy rápido de lo que puede hacer txtAi en unas pocas líneas, aquí tienes un primer ejemplo tomado de la documentación oficial: https://github.com/neuml/txtai/blob/master/examples/01_Introducing_txtai.ipynb
sequences:
path: google/flan-t5-small
workflow:
chain:
tasks:
- task: template
template: Translate '{statement}' to {language} if it's English
action: sequences
- task: template
template: What language is the following text? {text}
action: sequences
Iniciamos un servidor:
CONFIG=workflow.yaml /usr/local/bin/uvicorn "txtai.api:app"
Y voilà, conectado directamente con FastApi, tienes directamente una API lista para usar
http://127.0.0.1:8000/docs te da acceso directamente a un espacio swagger para que puedas jugar con tu configuración.
Ahora lanzamos una consulta en nuestra API y analicemos qué sucede.:
curl -X 'POST' \
'http://127.0.0.1:8000/workflow' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"name": "example1",
"elements":[
{"statement": "Hello, how are you", "language": "French"},
{"statement": "Hallo, wie geht'\''s dir", "language": "French"}
]
}'
La respuesta será:
[
"Czech",
"French"
]
Pero entonces, ¿qué ha pasado? Recuerda el flujo de trabajo de ejemplo:
sequences:
path: google/flan-t5-small
workflow:
chain:
tasks:
- task: template
template: Translate '{statement}' to {language} if it's English
action: sequences
- task: template
template: What language is the following text? {text}
action: sequences
En el proceso, le pedimos al Modelo que "traduzca al francés si el mensaje está en inglés", luego pasamos la salida de esta tarea directamente a la siguiente tarea: "Dime el idioma de este texto". En nuestro payload, la primera frase está en inglés, así que el modelo nos la traducirá, la segunda está en alemán, y no la traducirá. Pero, ¿por qué no reconoce el idioma alemán? De hecho, el ejemplo oficial usa google/flan-t5-large mientras que yo he puesto el flan-t5-small. Menos preciso. Lo intento de nuevo con el t5-large y obtendré
[
"French",
"German"
]
Esto es mejor, con un modelo un poco más grande, la precisión es mejor. Cuanto más grande sea tu modelo, más necesitarás una GPU con RAM. Hay un buen equilibrio que encontrar entre el hardware necesario y la calidad de la respuesta deseada.
Entonces ya entiendes que, con muy pocas líneas de código, tienes una API que puede hacer un montón de cosas interesantes. Podrás indexar tus archivos PDF, imágenes, todos los documentos de tu empresa y hacer búsquedas inteligentes sobre ellos. O incluso construir una base de datos para preguntas y respuestas e interrogar un motor de búsqueda semántico en el idioma de tu elección para el idioma de tu elección. Las posibilidades solo están limitadas por tu imaginación/necesidad.
Así que todo esto es genial, pero si necesitas un poco más de flexibilidad. Vemos bien que en la documentación la lista de Task es grande y la mayoría de las cosas funcionan solas. Excepto que todos lo saben. Raramente estamos en un caso donde todo está ya presente y es allí donde hay que empezar a hacer las cosas uno mismo a mano.
Entonces, como ejemplo, vamos a crear nuestro propio flujo de trabajo, con nuestra propia tarea en un endpoint que ni siquiera hemos imaginado.
Por lo tanto, esto es lo que queremos:
- Una API del tipo: /translate en POST con un payload de este tipo:
[
{
"html": "Mon <div>text à</div> moi ",
"lang": "en"
}
]
JSON.stringify($('#test_json').html()) en cualquier sitio te dará contenido para el ejemplo.
- Queremos recuperar contenido HTML y traducirlo. Y para terminar, por supuesto, devolver el resultado.
Dirás que es muy simple. Y no estarías del todo equivocado. Porque lo es, de hecho. Pero como todo, una vez que tienes un ejemplo frente a ti, es muy simple. Los ejemplos simples no son comunes, aún tuve que buscar y probar un poco.
Por lo tanto, te invito a leer el código y los comentarios deberían guiarte sobre lo que hay que hacer.
Por lo tanto, tenemos 2 archivos: main.py y TranslateHtml.py. Main siendo nuestro programa principal y TranslateHtml nuestra clase que nos sirve de tarea para nuestro flujo de trabajo.
from txtai.pipeline import Translation
from bs4 import BeautifulSoup
class TranslateHtml:
def __init__(self):
self.translate = Translation()
def __call__(self, datas):
results = []
for data in datas:
html = data['html']
lang = data['lang']
translated = self.translate_html(html, lang)
results.append(translated)
return results
def translate_html(self, html, lang):
html = html.replace("\/", "/")
soup = BeautifulSoup(html, 'html.parser')
for element in soup.find_all(string=True):
if element.parent.name in ['p', 'li', 'h1', 'h2', 'h3', 'span']:
original_text = element.string
translated_text = self.translate_to(original_text, lang)
if translated_text:
element.string.replace_with(translated_text)
return str(soup)
def translate_to(self, text, lang="fr"):
return self.translate(text, lang)
Así que tenemos una clase, bastante simple. Tiene que ser llamable y devolvernos una lista de resultados. Por supuesto, me inspiré en la clase de Task Translation para ver cómo se debe organizar el código.
Recuérdalo, la idea es hacer una tarea personalizada que debería poder encadenarse con las demás que podríamos usar en un flujo de trabajo. Cabe destacar que incluso es posible crear flujos de trabajo de flujos de trabajo. Lo cual puede ser muy útil si se desea organizar sus tareas/flujos de trabajo en forma de bloques bien elaborados.
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from fastapi.encoders import jsonable_encoder
from typing import List
from txtai.workflow import Workflow, Task
from TranslateHtml import TranslateHtml
# Définition du modèle Pydantic pour les données d'entrée
class TranslationRequest(BaseModel):
html: str
lang: str
# Initialisation de FastAPI
app = FastAPI()
# Déclaration de notre Tache perso
translate_html = TranslateHtml()
# Déclaration de notre workflow.
workflow = Workflow(
[
Task(lambda x: translate_html(x))
]
)
# Définition de l'endpoint POST
@app.post("/translate/")
async def translate(requests: List[TranslationRequest]):
try:
# Converti les requêtes Pydantic en dictionnaires
data = [jsonable_encoder(request) for request in requests]
# Exécution du workflow txtai
results = workflow(data)
return results
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
Observa nuestro flujo de trabajo. Podríamos encadenar varios seguidos para realizar una lista de tratamientos complejos.
Iniciamos nuestro servidor unicornio:
CONFIG=workflow.yaml /usr/local/bin/uvicorn "txtai.api:app"
export CUDA_VISIBLE_DEVICES="" && uvicorn main:app --reload
pongo CUDA_VISIBLE_DEVICES vacío para decir "no uses mi GPU".
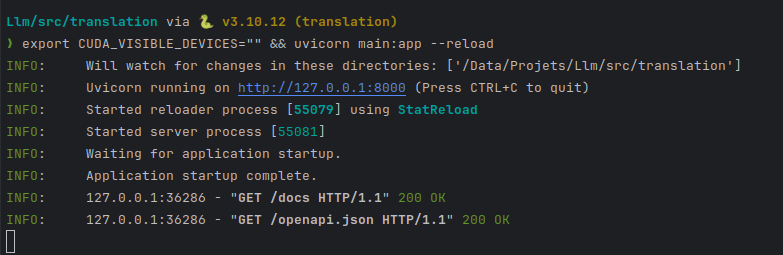
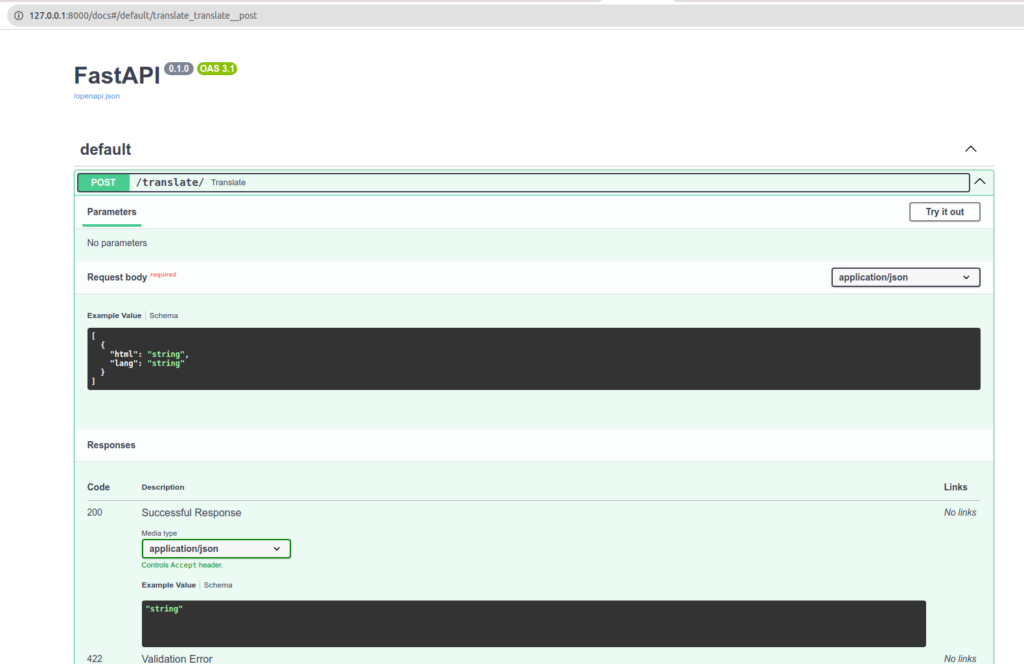
Vamos a verificar el tratamiento de nuestra API:
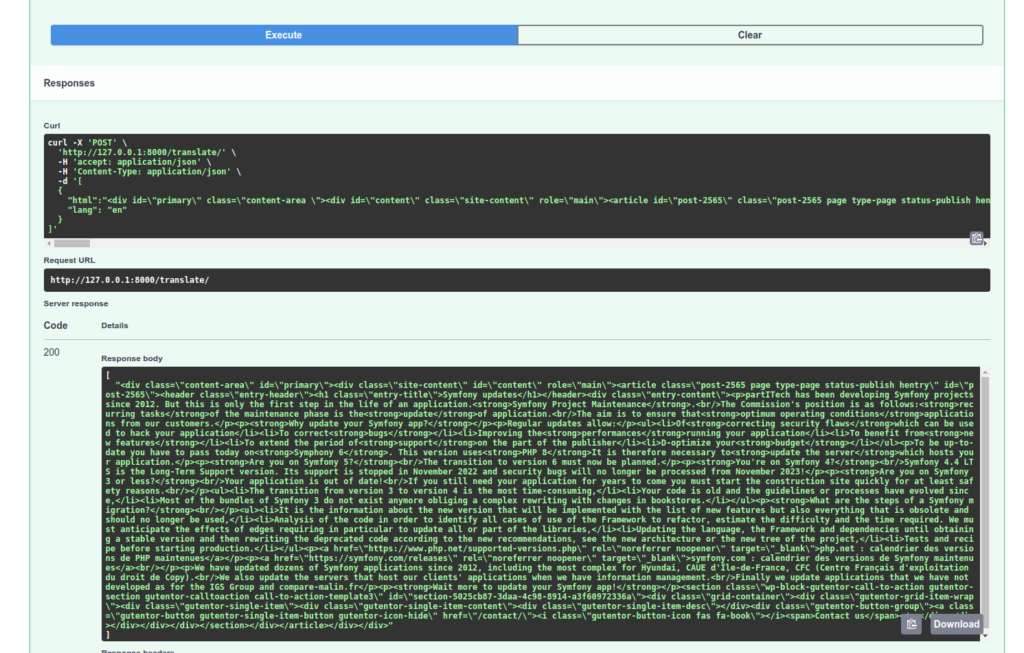
A tener en cuenta que la tarea de referencia translate utilizada en nuestra Tarea de conversión TranslateHtml elige automáticamente el modelo más adecuado para tu traducción. Además, si en mi llamada cambio y pongo "it", mi primera petición tendrá que esperar la descarga del modelo adecuado.
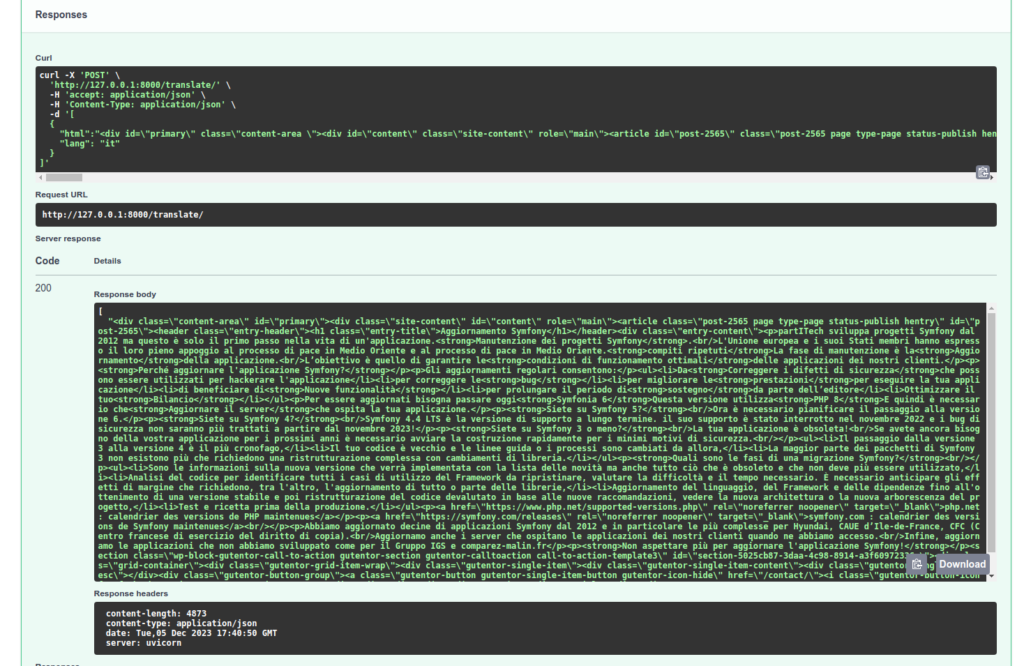
Ten en cuenta que otros modelos especializados harán un trabajo mejor de traducción. GPT-4 en particular, pero otros servicios hechos para esta tarea serán más apropiados. Y en cualquier caso, no reemplazará a un verdadero traductor y una revisión. Sin embargo, estos tratamientos de texto serán suficientes para clasificar tus documentos y consultar sobre ellos.
Así que aquí tienes una primera presentación de TxtAi, tendremos la oportunidad de hablar de ello muy pronto, ya que constituye una excelente alternativa a LlamaIndex.