Nell'universo in continua evoluzione dell'intelligenza artificiale e del trattamento del linguaggio naturale, txtai emerge come uno strumento rivoluzionario, soprattutto per coloro che si immergono nel mondo dei modelli di linguaggio su larga scala (LLMs). Immaginate un ponte tra voi e un ventaglio di LLMs potenti, dove txtai gioca il ruolo di intermediario facilitante, semplificando e amplificando le vostre interazioni con queste tecnologie complesse.
Connettività Estesa con i LLMs
Txtai si distingue per la sua capacità di connettersi a vari LLMs. Che sia GPT-3, BERT, o altri modelli all'avanguardia, txtai agisce come un canale unificato, che vi permette di accedere a queste potenze di calcolo senza il fastidio di configurazioni complesse. Per lo sviluppatore, ciò significa una riduzione significativa del tempo e dello sforzo necessario per integrare questi modelli nelle proprie applicazioni.
Funzionalità Preconfigurate per una Facilità d'Uso
Uno dei maggiori punti di forza di txtai è la pre-configurazione delle sue diverse funzioni di trattamento del testo. Classificazione, riassunto, traduzione, e molte altre attività di NLP sono pronte all'uso, richiedendo solo un minimo intervento dello sviluppatore. Questa facilità d'uso rende txtai particolarmente attraente per coloro che desiderano sfruttare la potenza dei LLMs senza immergersi nei dettagli tecnici.
Workflow Personalizzabile per Compiti Raggruppati
La vera magia di txtai risiede nella sua capacità di raggruppare compiti in workflow personalizzabili. Questo apre un immenso potenziale per le aziende permettendo loro di incatenare operazioni di NLP in sequenze logiche, automatizzando così processi complessi. Che si tratti di analizzare sentimenti, generare riassunti di documenti, o eseguire ricerche approfondite, txtai rende queste attività non solo possibili, ma anche sorprendentemente semplici.
Ricerche Intelligenti e Altro Ancora
Oltre alle ricerche testuali di base, txtai eccelle nella realizzazione di ricerche intelligenti, comprendendo il contesto e la sfumatura delle query. Questa capacità di interpretare e rispondere in maniera intelligente alle richieste di ricerca rende txtai non solo uno strumento potente per gli sviluppatori, ma anche un vantaggio strategico per le aziende che cercano di sfruttare al massimo i dati testuali.
In sintesi, txtai non è soltanto uno strumento, è un facilitatore, un amplificatore di possibilità nel campo dell'intelligenza artificiale e del trattamento del linguaggio naturale. Con txtai, gli sviluppatori hanno accesso senza precedenti a una gamma di funzionalità avanzate in NLP, godendo allo stesso tempo di una semplicità d'uso e di una adattabilità eccezionali.
Per darvi un esempio molto veloce di quello che può fare txtAi in poche righe ecco un primo esempio tratto dalla documentazione ufficiale: https://github.com/neuml/txtai/blob/master/examples/01_Introducing_txtai.ipynb ```ỲAML sequences: path: google/flan-t5-small workflow: chain: tasks: - task: template template: Translate '{statement}' to {language} if it's English action: sequences - task: template template: What language is the following text? {text} action: sequences
Avviamo un server: ```Basch
CONFIG=workflow.yaml /usr/local/bin/uvicorn "txtai.api:app"
E ecco, collegato direttamente con FastApi, avete direttamente un'API pronta all'uso 
http://127.0.0.1:8000/docs vi dà direttamente accesso a uno spazio swagger per permettervi di giocare con la vostra configurazione.
Ora lanciamo una richiesta sulla nostra API e analizziamo cosa succede: ```Basch
curl -X 'POST'
'http://127.0.0.1:8000/workflow'
-H 'accept: application/json'
-H 'Content-Type: application/json'
-d '{
"name": "example1",
"elements":[
{"statement": "Hello, how are you", "language": "French"},
{"statement": "Hallo, wie geht'''s dir", "language": "French"}
]
}'
La risposta sarà: ```Json
[
"Czech",
"French"
]
Ma cosa è successo? Ricordate il workflow d'esempio: ```YAML sequences: path: google/flan-t5-small workflow: chain: tasks: - task: template template: Translate '{statement}' to {language} if it's English action: sequences - task: template template: What language is the following text? {text} action: sequences
Nel pipeline, chiediamo al Modello di "tradurre in francese se il messaggio è in inglese", poi passiamo direttamente l'uscita di questo compito al compito seguente: "Dimmi la lingua di questo testo". Nel nostro payload, la prima frase è in inglese, quindi il modello ce la tradurrà, nella seconda, è in tedesco, quindi non la tradurrà. Ma perché non riconosce la lingua tedesca? In realtà l'esempio ufficiale utilizza `google/flan-t5-large` mentre io ho messo il `flan-t5-small`. Meno preciso. Riprovo con il `t5-large` e questo darà risultati migliori.
```JSON
[
"French",
"German"
]
Maggiore è la dimensione del modello, più avrete bisogno di una GPU con RAM. C'è un buon rapporto da trovare tra il hardware necessario e la qualità della risposta desiderata. Avrete quindi capito, con pochissime righe di codice, avete un'API che può fare un mucchio di cose interessanti. Potrete indicizzare i vostri file PDF, le vostre immagini, tutti i documenti della vostra azienda e fare ricerche intelligenti su di essi. Oppure potrete creare un database per domande/risposte e interrogare un motore di ricerca semantico nella lingua che preferite.
Le possibilità sono limitate solo dalla vostra immaginazione/bisogno. Quindi tutto ciò è fantastico, ma se abbiamo bisogno di un po' più di flessibilità. Vediamo bene che nella documentazione l'elenco delle Task è grande e la maggior parte delle cose si fanno da sole. Tranne che sappiamo bene. Raramente ci troviamo in un caso dove tutto è già presente ed è qui che bisogna iniziare a fare le cose da soli a mano.
Quindi per l'esempio, creeremo il nostro workflow personalizzato, con il nostro compito personalizzato su un endpoint che ci saremo anche immaginati.
Quindi ecco cosa vogliamo:
1- Un'API del tipo: /translate in POST con un payload di questo tipo: ```Json [ { "html": "Mon
**JSON.stringify($('#test_json').html())** su qualsiasi sito vi darà contenuto per l'esempio.
2. Quindi vogliamo recuperare contenuto HTML e tradurlo. E per finire, naturalmente, restituire il risultato.
Potreste pensare che sia super semplice. E non avreste del tutto torto. Perché, in effetti, lo è. Ma come sempre, una volta che si ha un esempio davanti agli occhi, è molto semplice. Non essendoci molti esempi semplici, ho comunque dovuto cercare e fare tentativi. Quindi vi propongo di leggere il codice, e i commenti dovrebbero guidarvi sui passaggi da seguire.
Abbiamo quindi 2 file: `main.py` e `TranslateHtml.py`. `Main` essendo il nostro programma principale e `TranslateHtml` la nostra classe che ci serve come compito per il nostro workflow. ```Python
from txtai.pipeline import Translation
from bs4 import BeautifulSoup
class TranslateHtml:
def __init__(self):
self.translate = Translation()
def __call__(self, datas):
results = []
for data in datas:
html = data['html']
lang = data['lang']
translated = self.translate_html(html, lang)
results.append(translated)
return results
def translate_html(self, html, lang):
html = html.replace("\/", "/")
soup = BeautifulSoup(html, 'html.parser')
for element in soup.find_all(string=True):
if element.parent.name in ['p', 'li', 'h1', 'h2', 'h3', 'span']:
original_text = element.string
translated_text = self.translate_to(original_text, lang)
if translated_text:
element.string.replace_with(translated_text)
return str(soup)
def translate_to(self, text, lang="fr"):
return self.translate(text, lang)
Abbiamo quindi una classe, abbastanza semplice. Deve essere richiamabile e ci deve restituire un array di risultati. Mi sono, ovviamente, ispirato alla classe di Task Translation per vedere come doveva essere organizzato il codice. Ricordiamolo, l'idea è di creare un compito personalizzato che dovrebbe poter essere incatenato con altri che potremmo utilizzare in un workflow. Da notare che è persino possibile creare workflow di workflow. Ciò può essere molto utile se si vuole organizzare i propri compiti/workflow sotto forma di mattoni ben elaborati. ```Python from fastapi import FastAPI, HTTPException from pydantic import BaseModel from fastapi.encoders import jsonable_encoder from typing import List from txtai.workflow import Workflow, Task from TranslateHtml import TranslateHtml
class TranslationRequest(BaseModel): html: str lang: str
app = FastAPI()
translate_html = TranslateHtml()
workflow = Workflow( [ Task(lambda x: translate_html(x)) ] )
@app.post("/translate/") async def translate(requests: List[TranslationRequest]): try: # Converti les requêtes Pydantic en dictionnaires data = [jsonable_encoder(request) for request in requests] # Exécution du workflow txtai results = workflow(data) return results except Exception as e: raise HTTPException(status_code=500, detail=str(e))
Notate il nostro workflow. Potremmo incatenarne diversi di seguito per incatenare una lista di trattamenti complessi.
Accendiamo il nostro server unicorn: ```Basch
CONFIG=workflow.yaml /usr/local/bin/uvicorn "txtai.api:app"
export CUDA_VISIBLE_DEVICES="" && uvicorn main:app --reload
Metto CUDA_VISIBLE_DEVICES vuoto per dire "non usare la mia GPU". 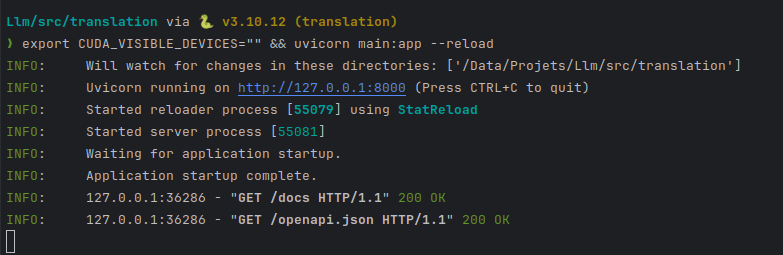
Verificheremo il trattamento della nostra API: 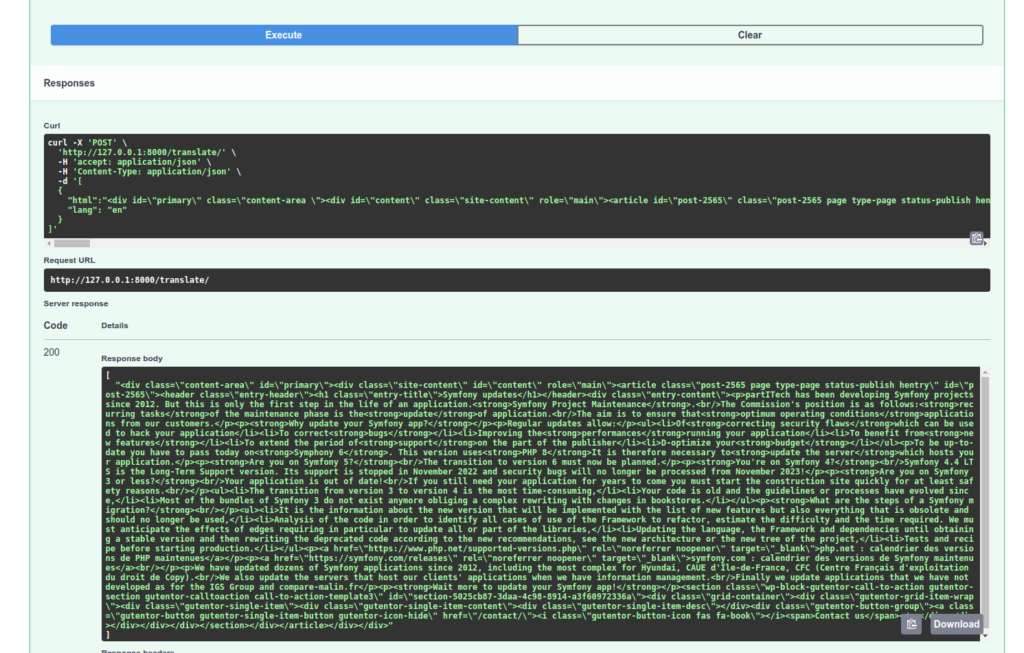
Da notare che il compito di riferimento translate utilizzato nel nostro Task di conversione TranslateHtml sceglie automaticamente il modello più appropriato per la vostra traduzione! Inoltre, se nel mio appello cambio e metto "it", la mia prima richiesta dovrà aspettare il download del modello adeguato. 
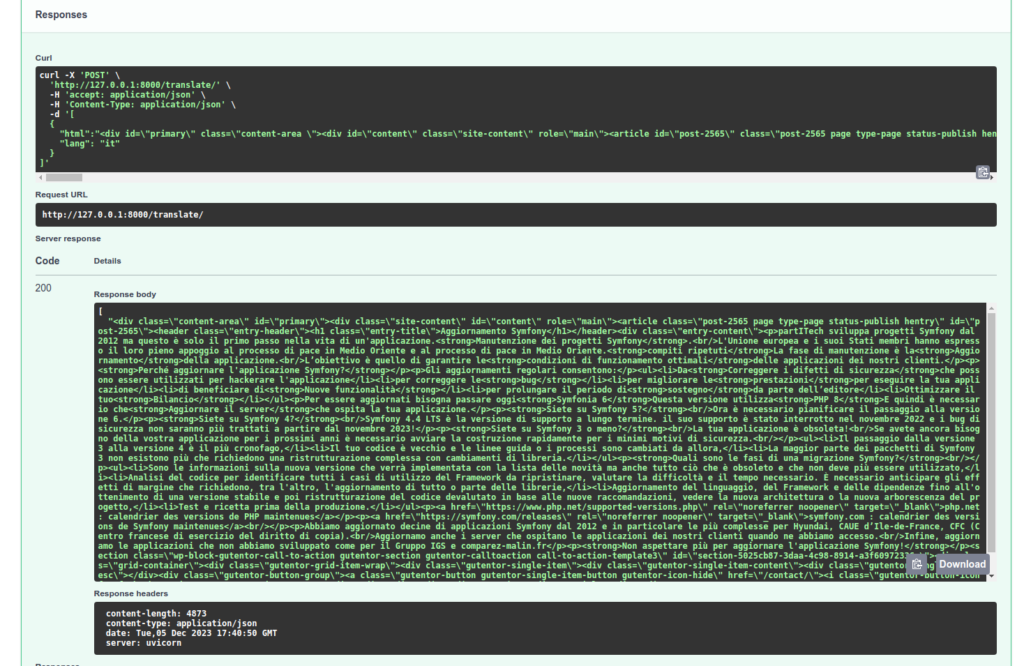
Tenete a mente che altri modelli specializzati faranno un lavoro migliore di traduzione. GPT-4 in particolare, ma altri servizi fatti per questo compito saranno più adatti. E comunque, non sostituiranno un vero traduttore e una revisione. D'altra parte, questi trattamenti di testi saranno sufficienti per classificare i vostri documenti e fare ricerche su di essi.
Ecco quindi una prima presentazione di TxtAi, ne parleremo ancora molto presto perché costituisce un'eccellente alternativa a LlamaIndex.