Giới thiệu về txtai: Đơn giản hoá và Tăng cường Sức mạnh của LLMs cho các Nhà phát triển Trong vũ trụ liên tục phát triển của trí thông minh nhân tạo và xử lý ngôn ngữ tự nhiên, txtai nổi lên như một công cụ cách mạng, đặc biệt là cho những người đang bước vào thế giới của mô hình ngôn ngữ quy mô lớn (LLMs). Hãy tưởng tượng một cây cầu giữa bạn và một loạt các LLMs mạnh mẽ, nơi txtai đảm nhận vai trò trung gian giúp đơn giản hóa, và tăng cường tương tác của bạn với những công nghệ phức tạp này.
Kết nối Mở rộng với các LLMs
Txtai nổi bật với khả năng kết nối với nhiều LLMs khác nhau. Cho dù là GPT-3, BERT, hay các mô hình tiên tiến khác, txtai hành động như một kênh thống nhất, giúp bạn tiếp cận với những sức mạnh tính toán mà không cần lo lắng về việc cấu hình phức tạp. Đối với nhà phát triển, điều này có nghĩa là giảm đáng kể thời gian và công sức cần thiết để tích hợp các mô hình này vào ứng dụng của họ.
Tính năng Được Cấu hình Sẵn cho Sự Tiện lợi trong Sử dụng
Một trong những lợi thế chính của txtai là việc cấu hình sẵn các chức năng xử lý văn bản đa dạng của nó. Phân loại, tóm tắt, dịch thuật, và nhiều nhiệm vụ NLP khác đã sẵn sàng để sử dụng, chỉ cần một chút can thiệp từ phía nhà phát triển. Sự dễ dàng trong sử dụng làm cho txtai trở nên đặc biệt hấp dẫn cho những người muốn khai thác sức mạnh của các LLMs mà không cần phải đắm mình vào các chi tiết kỹ thuật.
Quy trình Làm việc Tùy chỉnh cho các Nhiệm vụ Nhóm
Phép thuật thực sự của txtai nằm ở khả năng tổ chức các nhiệm vụ thành các quy trình làm việc tùy chỉnh. Điều này mở ra khả năng rộng lớn cho các doanh nghiệp bằng cách cho phép họ xâu chuỗi các hoạt động NLP thành chuỗi logic, tự động hóa như vậy các quy trình phức tạp. Dù là phân tích cảm xúc, tạo tóm tắt tài liệu, hay thực hiện tìm kiếm sâu rộng, txtai không chỉ làm cho những nhiệm vụ này trở nên khả thi, mà còn đáng ngạc nhiên về mức độ đơn giản.
Tìm kiếm Thông minh và Hơn thế nữa
Không chỉ giới hạn ở tìm kiếm văn bản cơ bản, txtai còn xuất sắc trong việc thực hiện tìm kiếm thông minh, hiểu được ngữ cảnh và sắc thái của các yêu cầu. Khả năng này giúp txtai không chỉ là một công cụ mạnh mẽ cho các nhà phát triển, mà còn là một tài sản chiến lược cho các doanh nghiệp mong muốn khai thác tối đa dữ liệu văn bản.
Tóm lại, txtai không chỉ là một công cụ, nó là một nhà tạo lập, một bậc thầy của các khả năng trong lĩnh vực trí thông minh nhân tạo và xử lý ngôn ngữ tự nhiên. Với txtai, các nhà phát triển có quyền truy cập chưa từng có đến một loạt tính năng NLP tiên tiến, đồng thời được hưởng lợi từ sự đơn giản trong sử dụng và khả năng thích ứng đặc biệt.
Để cho bạn một ví dụ nhanh chóng về những gì txtAi có thể làm trong vài dòng mã, đây là một ví dụ đầu tiên được trích từ tài liệu chính thức: https://github.com/neuml/txtai/blob/master/examples/01_Introducing_txtai.ipynb
sequences:
path: google/flan-t5-small
workflow:
chain:
tasks:
- task: template
template: Translate '{statement}' to {language} if it's English
action: sequences
- task: template
template: What language is the following text? {text}
action: sequences
Chúng ta khởi động một máy chủ:
CONFIG=workflow.yaml /usr/local/bin/uvicorn "txtai.api:app"
Và voila, kết nối trực tiếp với FastApi, bạn có ngay một api sẵn sàng sử dụng  http://127.0.0.1:8000/docs ngay lập tức cung cấp cho bạn quyền truy cập vào một không gian swagger để bạn có thể điều khiển cấu hình của mình. Bây giờ chúng ta hãy gửi một yêu cầu đến API của mình và phân tích xem điều gì đã xảy ra:
http://127.0.0.1:8000/docs ngay lập tức cung cấp cho bạn quyền truy cập vào một không gian swagger để bạn có thể điều khiển cấu hình của mình. Bây giờ chúng ta hãy gửi một yêu cầu đến API của mình và phân tích xem điều gì đã xảy ra:
curl -X 'POST' \
'http://127.0.0.1:8000/workflow' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"name": "example1",
"elements":[
{"statement": "Hello, how are you", "language": "French"},
{"statement": "Hallo, wie geht'\''s dir", "language": "French"}
]
}'
Câu trả lời sẽ là:
[
"Czech",
"French"
]
Nhưng điều gì đã xảy ra vậy? Hãy nhớ lại quy trình làm việc mẫu:
sequences:
path: google/flan-t5-small
workflow:
chain:
tasks:
- task: template
template: Translate '{statement}' to {language} if it's English
action: sequences
- task: template
template: What language is the following text? {text}
action: sequences
Trong quy trình làm việc, chúng ta yêu cầu Mô hình "dịch sang tiếng Pháp nếu thông điệp là tiếng Anh", chúng ta trực tiếp chuyển kết quả của nhiệm vụ này đến nhiệm vụ tiếp theo: "Hãy cho tôi biết ngôn ngữ của văn bản này". Trong payload của chúng ta, câu đầu tiên là tiếng Anh, vì vậy mô hình sẽ dịch nó, trong câu thứ hai, là tiếng Đức, nó không dịch. Nhưng tại sao nó không nhận diện tiếng Đức? Thực tế là ví dụ chính thức sử dụng google/flan-t5-large trong khi tôi đã sử dụng flan-t5-small. Ít chính xác hơn. Mình sẽ thử lại với t5-large và kết quả sẽ là Đó là một cải thiện, với một mô hình lớn hơn, độ chính xác là tốt hơn. Càng có mô hình lớn, bạn sẽ càng cần GPU với nhiều RAM. Có một tỷ lệ tốt cần tìm giữa phần cứng cần thiết và chất lượng phản hồi mong muốn.
[
"French",
"German"
]
Bạn sẽ hiểu rằng, chỉ với vài dòng mã, bạn đã có một API có thể thực hiện nhiều thứ thú vị. Ban có thể chỉ mục hóa các tập tin PDF, hình ảnh, tất cả các tài liệu của công ty và thực hiện các truy vấn thông minh trên chúng. Hoặc bạn có thể tạo một cơ sở dữ liệu cho các câu hỏi/trả lời và thăm dò một công cụ tìm kiếm ngữ nghĩa trong ngôn ngữ bạn chọn cho ngôn ngữ mà bạn chọn. Những khả năng không giới hạn ngoài trí tưởng tượng/nhu cầu của bạn.
Vì vậy, tất cả điều đó rất tuyệt, nhưng nếu chúng ta cần một chút linh hoạt hơn nữa. Chúng ta thấy rằng trong tài liệu, danh sách các Task là lớn và hầu hết mọi thứ đều tự xử lý. Nhưng chúng ta cũng biết rằng. Hiếm khi mọi thứ đã có sắn và đó là khi bạn cần bắt đầu làm mọi thứ một cách thủ công. Vậy để mẫu một ví dụ, chúng ta sẽ tạo ra quy trình làm việc của riêng mình, với nhiệm vụ của riêng mình với một điểm cuối mà chúng tôi thậm chí đã tưởng tượng ra. Nên đây là những gì chúng tôi muốn:
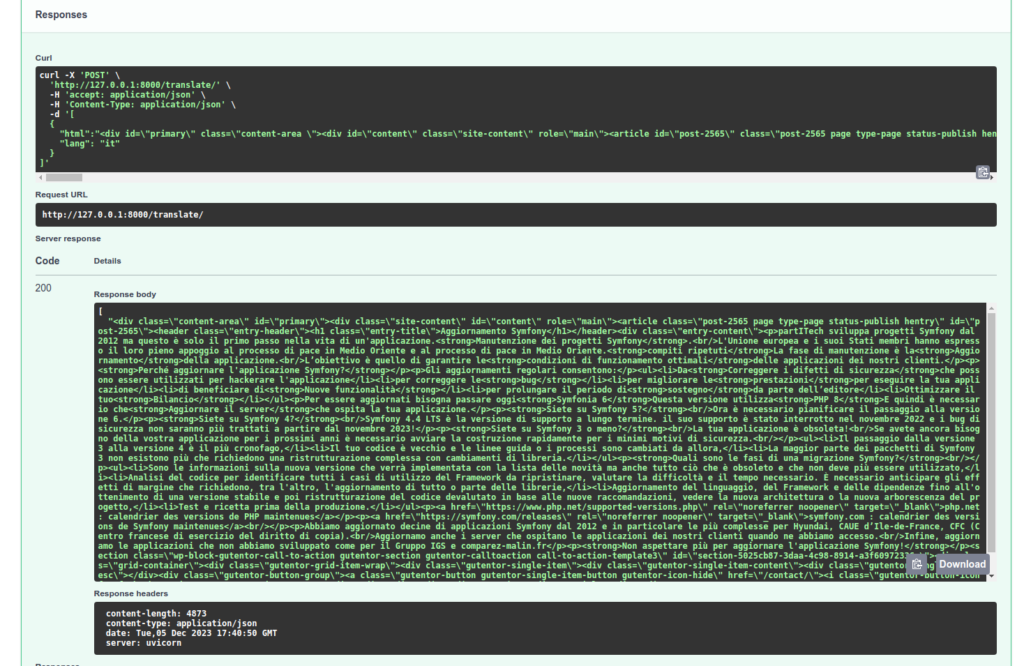
- Một api của loại: /translate trong POST với một payload như sau:
[
{
"html": "Mon <div>text à</div> moi ",
"lang": "en"
}
]
JSON.stringify($('#test_json').html()) trên bất kỳ trang web nào sẽ cung cấp cho bạn nội dung cho ví dụ.
- Vì vậy, chúng tôi muốn thu hồi nội dung HTML và dịch nó. Và cuối cùng, tất nhiên, trả lại kết quả.
Bạn sẽ nói, đó là rất đơn giản. Và bạn không hoàn toàn sai. Bởi vì thực sự là như vậy. Nhưng giống như mọi thứ, một khi bạn có một ví dụ trước mắt, mọi thứ rất đơn giản. Các ví dụ đơn giản không phổ biến, tôi vẫn phải tìm kiếm và thử nghiệm một chút. Vì vậy, tôi đề xuất bạn đọc mã và các bình luận sẽ hướng dẫn bạn cách tiếp tục.
Chúng tôi có hai tệp: main.py và TranslateHtml.py. Main là chương trình chính của chúng tôi và TranslateHtml là lớp chúng tôi sử dụng như một nhiệm vụ cho quy trình làm việc của chúng tôi.
from txtai.pipeline import Translation
from bs4 import BeautifulSoup
class TranslateHtml:
def __init__(self):
self.translate = Translation()
def __call__(self, datas):
results = []
for data in datas:
html = data['html']
lang = data['lang']
translated = self.translate_html(html, lang)
results.append(translated)
return results
def translate_html(self, html, lang):
html = html.replace("\/", "/")
soup = BeautifulSoup(html, 'html.parser')
for element in soup.find_all(string=True):
if element.parent.name in ['p', 'li', 'h1', 'h2', 'h3', 'span']:
original_text = element.string
translated_text = self.translate_to(original_text, lang)
if translated_text:
element.string.replace_with(translated_text)
return str(soup)
def translate_to(self, text, lang="fr"):
return self.translate(text, lang)
Vì vậy, chúng ta có một lớp, khá đơn giản. Nó phải có thể gọi và trả lại một mảng kết quả. Tôi đã, dĩ nhiên, được truyền cảm hứng từ lớp Task Translation để xem mã phải được tổ chức như thế nào. Hãy nhớ lại, ý tưởng là tạo ra một nhiệm vụ tùy chỉnh mà có thể được xâu chuỗi với những nhiệm vụ khác mà chúng ta có thể sử dụng trong một quy trình làm việc. Đáng chú ý là bạn thậm chí có thể tạo các quy trình làm việc từ các quy trình làm việc. Điều này có thể rất hữu ích nếu bạn muốn tổ chức các nhiệm vụ/quy trình làm việc của mình dưới dạng các khối được phát triển kỹ lưỡng.
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from fastapi.encoders import jsonable_encoder
from typing import List
from txtai.workflow import Workflow, Task
from TranslateHtml import TranslateHtml
# Définition du modèle Pydantic pour les données d'entrée
class TranslationRequest(BaseModel):
html: str
lang: str
# Initialisation de FastAPI
app = FastAPI()
# Déclaration de notre Tache perso
translate_html = TranslateHtml()
# Déclaration de notre workflow.
workflow = Workflow(
[
Task(lambda x: translate_html(x))
]
)
# Définition de l'endpoint POST
@app.post("/translate/")
async def translate(requests: List[TranslationRequest]):
try:
# Converti les requêtes Pydantic en dictionnaires
data = [jsonable_encoder(request) for request in requests]
# Exécution du workflow txtai
results = workflow(data)
return results
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
Xin lưu ý về quy trình làm việc của chúng tôi. Chúng tôi có thể xâu chuỗi nhiều cái liên tiếp để tạo một danh sách các xử lý phức tạp.
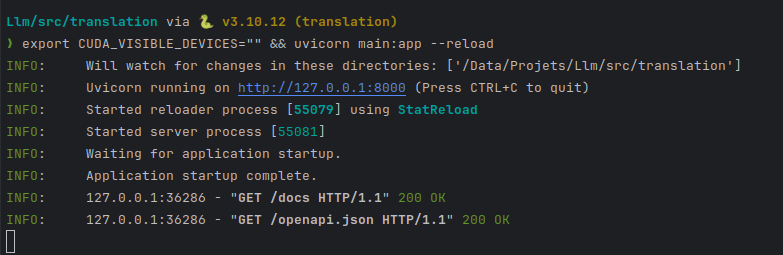
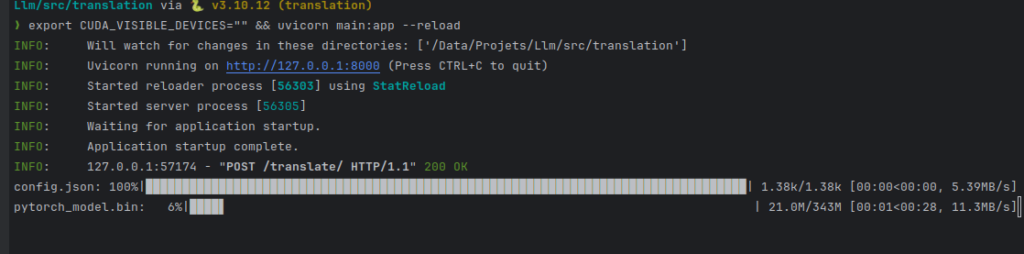
Chúng tôi khởi động máy chủ unicorn của chúng tôi:
CONFIG=workflow.yaml /usr/local/bin/uvicorn "txtai.api:app"
export CUDA_VISIBLE_DEVICES="" && uvicorn main:app --reload
tôi đưa CUDA_VISIBLE_DEVICES vào không gian để nói "đừng sử dụng GPU của tôi".
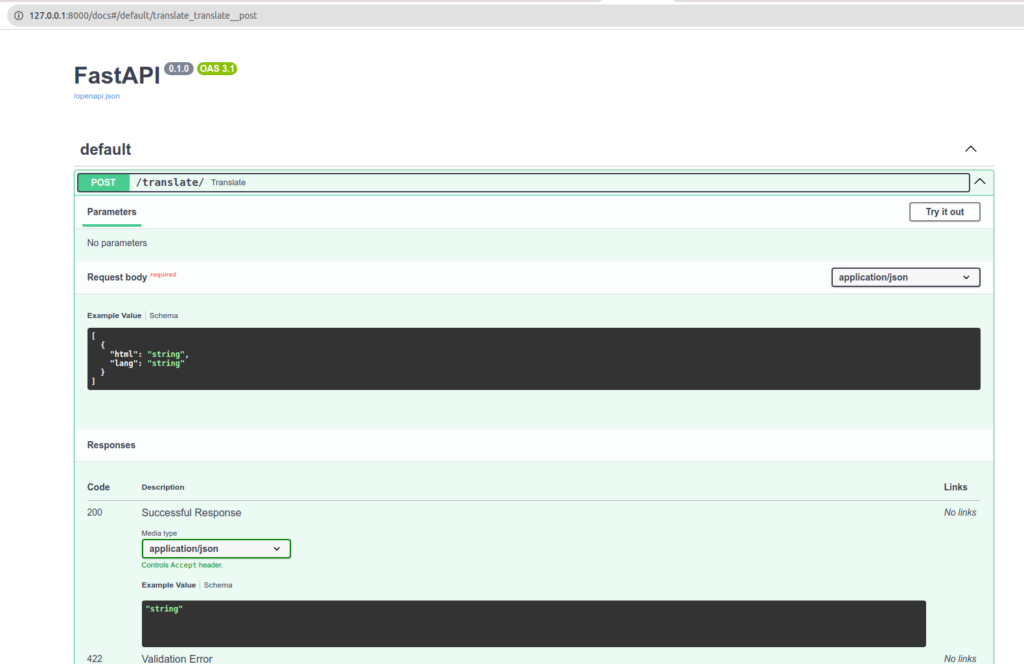
Chúng tôi sẽ kiểm tra xử lý của API của mình:
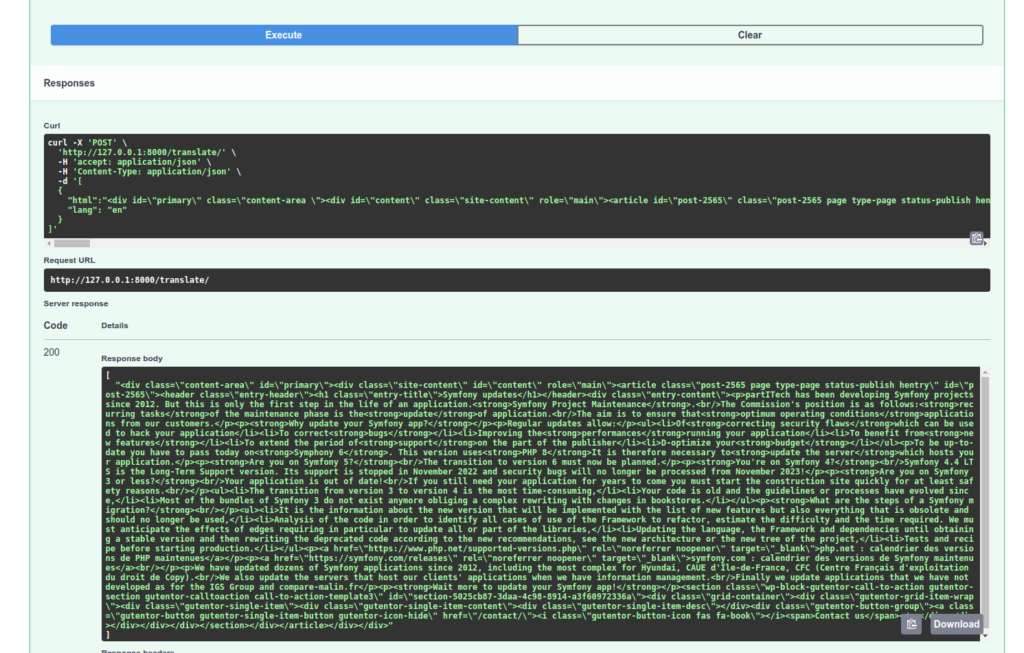
Để ý rằng nhiệm vụ dịch thuật tham chiếu được sử dụng trong Nhiệm vụ chuyển đổi Dịch thuật của chúng tôi tự động chọn mô hình phù hợp nhất với bản dịch của bạn! Ngoài ra, nếu trong cuộc gọi của mình tôi thay đổi và đặt "it", yêu cầu đầu tiên của tôi sẽ phải chờ tải xuống mô hình phù hợp.
Hãy nhớ rằng các mô hình chuyên biệt khác sẽ thực hiện công việc dịch thuật tốt hơn. Đặc biệt là GPT-4, nhưng các dịch vụ khác được tạo ra cho nhiệm vụ này sẽ thích hợp hơn. Và trong mọi trường hợp, nó sẽ không thay thế được một biên dịch viên thực sự và việc đọc lại. Tuy nhiên, những xử lý văn bản này sẽ đủ để phân loại tài liệu của bạn và truy vấn trên chúng. Vì vậy, đây là một bản giới thiệu đầu tiên về TxtAi, chúng tôi sẽ có cơ hội để nói về nó sớm hơn bởi vì nó tạo ra một lựa chọn thay thế tuyệt vời cho LlamaIndex.