Llama CPP es una nueva herramienta diseñada para ejecutar modelos de lenguaje directamente en C/C++. Esta herramienta está especialmente optimizada para procesadores Apple Silicon gracias al uso de la tecnología ARM NEON y del framework Accelerate.
También ofrece compatibilidad AVX2 para sistemas basados en arquitecturas x86. Funcionando principalmente en la CPU, Llama CPP también incorpora la capacidad de cuantificación de 4 bits, aumentando así su eficiencia. Su ventaja es que permite ejecutar un modelo de lenguaje directamente en su computadora personal sin requerir una GPU con una gran cantidad de VRAM.
Para simplificar, no es necesario vender su coche para probar los últimos modelos de moda. Seamos claros, aunque la herramienta le permite sumergirse de cabeza y a bajo costo en el mundo de los LLM, será necesario armarse de paciencia. Porque los tiempos de procesamiento a veces son monstruosos. ¿Hacemos la prueba juntos? Verá, no es raro esperar 5 minutos para obtener una respuesta. Y no importa, la idea aquí es hacer funcionar el sistema en su estación de trabajo. Entenderá por qué las estrellas del alojamiento le piden unos cientos/miles de euros para ejecutar sus modelos en la nube.
A la fecha, aquí está la lista de los modelos compatibles:
- LLaMA 🦙
- LLaMA 2 🦙🦙
- Falcon
- Alpaca
- GPT4All
- Chinese LLaMA / Alpaca y Chinese LLaMA-2 / Alpaca-2
- Vigogne (Francés)
- Vicuña
- Koala
- OpenBuddy 🐶 (Multilingüe)
- Pygmalion/Metharme
- WizardLM
- Baichuan 1 & 2 + derivados
- Aquila 1 & 2
- Modelos de Starcoder
- Mistral AI v0.1
- Refact
- Persimmon 8B
- MPT
- Bloom
- StableLM-3b-4e1t
El primer paso será entonces instalar y compilar Llama cpp. Partimos del principio de que usted es un desarrollador, y como buen desarrollador, utiliza Linux. ¿No es así? No importa, use Docker para simular una máquina que funcione con el mismo SO que este artículo, es decir, Ubuntu 22.04. Puede usar este docker-compose.yml por ejemplo:
version: '3.8'
services:
ubuntu:
image: ubuntu:22.04
command: /bin/bash
stdin_open: true
tty: true
working_dir: /workspace
Docker compose up
Docker compose exec ubuntu bash
¿Listo? Continuemos. Pre-requisito: instalar las herramientas necesarias para ejecutar el programa. Necesitará herramientas de compilación, así como herramientas que le permitan clonar proyectos de GitHub y un token que le dé acceso a Huggingface, el famoso repositorio de los LLM open source.
apt-get update
apt-get install -y git cmake g++ make curl gh python3-pip
curl -fsSL https://cli.github.com/packages/githubcli-archive-keyring.gpg | sudo dd of=/usr/share/keyrings/githubcli-archive-keyring.gpg
sudo chmod go+r /usr/share/keyrings/githubcli-archive-keyring.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/githubcli-archive-keyring.g
pg] https://cli.github.com/packages stable main" | sudo tee /etc/apt/sources.list.d/github-cli.list > /dev/null
pip install numpy
pip install sentencepiece
pip install -U "huggingface_hub[cli]"
Para crear un token de acceso de Hugging Face, aquí está el enlace (puede ser un poco complicado de encontrar en la interfaz): https://huggingface.co/settings/tokens Si aún no tiene un token en GitHub, aquí también hay un enlace: https://github.com/settings/tokens/new
Ahora, vamos a clonar y compilar llama.cpp.
# Cloner le dépôt Git de llama-cpp
gh repo clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# Compiler le projet
mkdir build
cd build
cmake ..
cmake --build . --config Release
A continuación, vamos a descargar el último modelo creado por MistralAi. Encontrará el modelo en Huggingface aquí: https://huggingface.co/mistralai
Para mayor claridad, puede agregar directamente llama.cpp a su entorno. Esto nos permitirá concentrarnos en los comandos sin contaminar nuestra consola con rutas que no nos aportan nada. Por ejemplo:
export PATH="/Data/Projets/Llm/src/Llama-cpp/llama.cpp/build/bin:$PATH"
Descarga del Modelo: reemplace $HUGGINGFACE_TOKEN por su token.
mkdir /Data/Projets/Llm/Models/mistralai
huggingface-cli login --token $HUGGINGFACE_TOKEN
huggingface-cli download mistralai/Mistral-7B-v0.1 --local-dir /Data/Projets/Llm/Models/mistralai
Sírvase un café, hay 15 gigas para descargar. Algunos archivos grandes serán solo enlaces simbólicos al directorio de caché. Puede especificar --cache-dir para escribirlos en otra partición si es necesario. Esto nos podría dar algo como esto:
huggingface-cli download mistralai/Mistral-7B-v0.1 --local-dir /Data/Projets/Llm/Models/mistralai --cache-dir /Data/Projets/Llm/Models/huggingface_cache/
Una vez que hemos descargado nuestros archivos en formato PyTorch, tendremos que proceder a una pequeña conversión. Volvemos a nuestro directorio llama.cpp y ejecutamos el siguiente comando:
python3 llama.cpp/convert.py /Data/Projets/Llm/Models/mistralai
--outfile /Data/Projets/Llm/Models/mistralai/Mistral-7B-v0.1.gguf
--outtype f16
¿Qué es este parámetro --outtype q8_0? Es la Cuantificación (quantization en inglés). La cuantificación es un proceso que busca reducir el tamaño y la complejidad de los modelos. Imagine un escultor que comienza con un enorme bloque de mármol y lo corta para crear una estatua. La cuantificación es como quitar partes del bloque para hacerlo más liviano y fácil de mover, asegurándose de que la estatua conserve su belleza y forma. En el contexto de los LLM, la cuantificación implica simplificar la representación de los pesos del modelo. Los pesos en un LLM son valores numéricos que determinan cómo el modelo reacciona a diferentes entradas. Al reducir la precisión de estos pesos (por ejemplo, de valores flotantes de 32 bits a valores de 8 bits), se reduce el tamaño general del modelo y la cantidad de cálculo necesario para ejecutarlo. Esto tiene varios beneficios. Primero, hace que el modelo sea más rápido y menos exigente en términos de energía, lo cual es crucial para aplicaciones en dispositivos móviles o servidores de baja capacidad. En segundo lugar, hace que la IA sea más accesible, ya que puede funcionar en una gama más amplia de dispositivos, incluidos aquellos que no tienen hardware informático de última generación. Sin embargo, la cuantificación debe manejarse con cuidado. Una reducción excesiva de la precisión puede llevar a una pérdida de rendimiento, donde el modelo se vuelve menos preciso o menos confiable. Por lo tanto, se trata de encontrar el equilibrio adecuado entre eficiencia y rendimiento.
-
Cuantificación de 2 bits (2-Bit Quantization) - q2_k: Utiliza Q4_K para los tensores attention.vw y feed_forward.w2, y Q2_K para los demás. Esto significa que ciertos tensores clave tienen una precisión ligeramente superior (4 bits) para mantener el rendimiento, mientras que los otros están más comprimidos (2 bits).
-
Cuantificación de 3 bits (3-Bit Quantization) - q3_k_l: Utiliza Q5_K para attention.wv, attention.wo, y feed_forward.w2, y Q3_K para los demás. Esto indica una precisión más alta (5 bits) para algunos tensores importantes, mientras que los otros están a 3 bits.
- q3_k_m: Usa Q4_K para los mismos tensores que q3_k_l, pero con una precisión ligeramente inferior (4 bits), y Q3_K para los demás.
- q3_k_s: Aplica una cuantificación Q3_K a todos los tensores, ofreciendo uniformidad pero con menos precisión.
- Cuantificación de 4 bits (4-Bit Quantization) - q4_0: Método original de cuantificación a 4 bits.
- q4_1: Ofrece una precisión más alta que q4_0, pero inferior a q5_0, con una inferencia más rápida que los modelos q5.
- q4_k_m: Usa Q6_K para la mitad de los tensores attention.wv y feed_forward.w2, y Q4_K para los demás.
- q4_k_s: Aplica Q4_K a todos los tensores.
- Cuantificación de 5 bits (5-Bit Quantization) - q5_0: Ofrece una precisión más alta pero requiere más recursos y ralentiza la inferencia.
- q5_1: Proporciona una precisión aún más alta a costa de un mayor uso de recursos y una inferencia más lenta.
- q5_k_m: Como q4_k_m, pero con Q6_K para algunos tensores y Q5_K para los demás.
- q5_k_s: Usa Q5_K para todos los tensores.
-
Cuantificación de 6 bits (6-Bit Quantization) - q6_k: Utiliza una cuantificación Q8_K para todos los tensores, ofreciendo una precisión relativamente alta.
-
Cuantificación de 8 bits (8-Bit Quantization) - q8_0: Este método alcanza una cuantificación casi indistinguible del formato float16, pero requiere muchos recursos y ralentiza la inferencia.
La precisión de un método de cuantificación depende de la cantidad de bits utilizada para representar los pesos del modelo.
-
La más precisa: El método q6_k (Cuantificación de 6 bits), que usa Q8_K para todos los tensores, probablemente sería el más preciso de nuestra lista. Utiliza 8 bits para cada peso, lo que permite una representación más detallada y cercana a los valores originales. Esto se traduce en una mejor preservación de las sutilezas y detalles del modelo, pero a costa de un mayor uso de recursos y potencialmente un tiempo de inferencia más largo.
-
La menos precisa: El método q2_k (Cuantificación de 2 bits) sería el menos preciso. Este método utiliza solo 2 bits para la mayoría de los tensores, con algunas excepciones a 4 bits (Q4_K) para los tensores attention.vw y feed_forward.w2. La representación a 2 bits es muy compacta, pero también es mucho más probable que pierda información importante, ya que solo puede representar cuatro valores diferentes por peso, en comparación con 256 valores en una cuantificación de 8 bits.
Esto es teoría, nuestra herramienta nos ofrece tres tipos de conversiones: --outtype {f32,f16,q8_0}
-
f32 (Float 32-bit): Es la representación estándar de alta precisión para los números de punto flotante en muchos cálculos informáticos, incluidos en los LLM. Cada peso es almacenado con una precisión de 32 bits, lo que ofrece una gran precisión pero también un gran tamaño de modelo y uso de recursos. Esta opción no es una forma de cuantificación sino más bien el formato estándar sin cuantificación.
-
f16 (Float 16-bit): Es una versión más compacta de f32, donde cada peso es almacenado con una precisión de 16 bits. Esto reduce el tamaño del modelo y la cantidad de cálculo necesaria, con una pequeña pérdida de precisión en comparación a f32. Aunque es una forma de compresión, técnicamente no es cuantificación en el sentido en que hemos discutido previamente.
-
q8_0 (8-Bit Quantization): Esto se refiere directamente al método de cuantificación de 8 bits mencionado anteriormente. En este método, cada peso es representado con 8 bits. Es la cuantificación más alta entre las opciones que usted ha dado y es casi comparable a f16 en términos de precisión. Ofrece un buen equilibrio entre la reducción del tamaño del modelo y la preservación de la precisión.
En resumen, f32 ofrece la mayor precisión pero con el mayor tamaño, f16 reduce ese tamaño a la mitad con una pequeña pérdida de precisión, y q8_0 reduce aún más el tamaño manteniendo una precisión que generalmente es suficiente para muchas aplicaciones. Estas opciones reflejan diferentes compensaciones entre la precisión y la eficiencia en términos de tamaño y cálculo.
-
f32: les dará un archivo de 27 gigabytes. Tendrá que asegurarse de tener suficiente RAM para esto. De hecho, Llama.cpp cargará todo el archivo en RAM. La ejecución simplemente se bloqueó en mi estación.
-
f16: les dará un archivo de 14 gigabytes. La ejecución de una instrucción dará esto:
main -m /Data/Projets/Llm/Models/mistralai/Mistral-7B-v0.1.gguf -i --interactive-first -r "### Human:" --temp 0 -c 2048 -n -1 --ignore-eos --repeat_penalty 1.2 --instruct
Tienen la opción de usar directamente un servidor. El siguiente comando les permitirá instalar llama-cpp así como un servidor compatible con OpenAPI.
pip install llama-cpp-python[server]
python3 -m llama_cpp.server --model /Data/Projets/Llm/Models/mistralai/Mistral-7B-v0.1.gguf --host 0.0.0.0 --port 8000
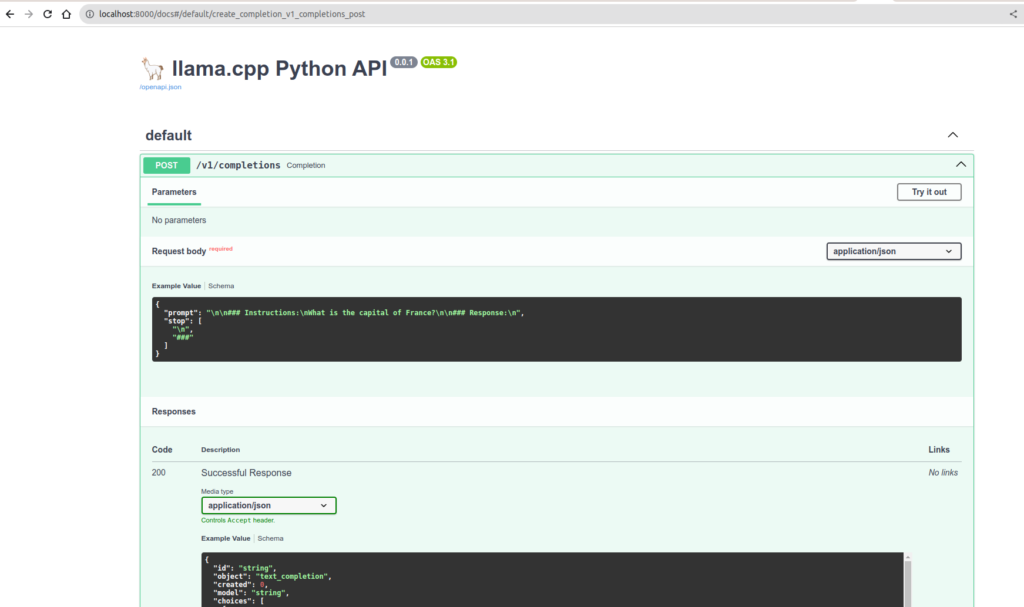
Ahora vamos a instalar una interfaz de cliente que conversará con nuestra API.
gh repo clone https://github.com/mckaywrigley/chatbot-ui.git
cd chatbot-ui/
docker compose up
He modificado un poco el docker-compose para calibrarlo con mi configuración.
version: '3.6'
services:
chatgpt:
build: .
ports:
- 3000:3000
restart: on-failure
environment:
- 'OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXX'
- 'OPENAI_API_HOST=http://host.docker.internal:8000'
- 'DEFAULT_MODEL=/Data/Projets/Llm/Models/mistralai/Mistral-7B-v0.1.gguf'
- 'NEXT_PUBLIC_DEFAULT_SYSTEM_PROMPT=You are a helpful and friendly AI assistant. Respond very concisely.'
- 'WAIT_HOSTS=http://host.docker.internal:8000/'
- 'WAIT_TIMEOUT=${WAIT_TIMEOUT:-3600}'
extra_hosts:
- "host.docker.internal:host-gateway"
El programa no está realmente diseñado para interactuar directamente con MistralAi. No he elegido necesariamente el ejemplo más simple. Sepan que con los modelos especificados como compatibles en el repositorio oficial, la integración es mejor.
Aquí hay una vista de lo que obtuve haciendo una pequeña pregunta sobre la receta de la mayonesa a través de Chat-ui.
Ahora veamos qué sucede cuando aumentamos la cuantificación a 8 bits con el tipo q8_0.
python3 llama.cpp/convert.py /Data/Projets/Llm/Models/mistralai --outfile /Data/Projets/Llm/Models/mistralai/Mistral-7B-v0.1_q8.gguf --outtype q8_0
main -m /Data/Projets/Llm/Models/mistralai/Mistral-7B-v0.1_q8.gguf -i --interactive-first -r "### Human:" --temp 0 -c 2048 -n -1 --ignore-eos --repeat_penalty 1.2 --instruct
Como pueden ver, ¡es mucho más rápido! Y totalmente utilizable.
Así termina esta pequeña presentación de una pila auto-alojada. Como pueden ver, con muy pocos medios, funciona. ¡Imagínense con hardware diseñado para ello! Sepan que MistralAi es una empresa francesa. Aparte del uso en una computadora portátil barata, sepa que todo el conjunto de herramientas empresariales está disponible para este modelo.